
msr14
URL
The dataset contains 90 GitHub projects and their folks that are not randomly selected and thus not representative of GitHub.
Challenge Chair
Overview
The International Working Conference on Mining Software Repositories (MSR) has hosted a mining challenge since 2006. With this challenge we call upon everyone interested to apply their tools to bring research and industry closer together by analyzing a common data set. The challenge is for researchers and practitioners who bravely put their mining tools and approaches on a dare.
In 2014, the challenge was on the GitHub data. We provide the data for the GitHub repository and you should use your brain, tools, computational power, and magic to uncover interesting findings related to it.
Challenge Data
This year, the focus of the challenge is the GitHub data. GitHub is a web-based service providing a collaborative software development environment and a social network for developers. We provide you with the dataset extracted from GHTorrent by Georgios Gousios.
When you use the data provided by the MSR 2014 Challenge, we ask you to cite it as following:
@inproceedings{Gousi13,
author = {Gousios, Georgios},
title = {The GHTorrent dataset and tool suite},
booktitle = {Proceedings of the 10th Working Conference on Mining Software Repositories},
series = {MSR'13},
year = {2013},
isbn = {978-1-4673-2936-1},
location = {San Francisco, CA, USA},
pages = {233--236},
numpages = {4},
url = {https://dl.acm.org/citation.cfm?id=2487085.2487132}
}
Dataset Description
The MSR 2014 challenge dataset is a (very) trimmed down version of the original GHTorrent dataset. It includes data from the top-10 starred software projects for the top programming languages on Github, which gives 90 projects and their forks. For each project, we retrieved all data including issues, pull requests organizations, followers, stars and labels (milestones and events not included). The dataset was constructed from scratch to ensure the latest information is in it.
Similarly to GHTorrent itself, the MSR challenge dataset comes in two flavours:
- A MongoDB database dump containing the results of querying the Github API. See format below.
- A MySQL database dump containing a queriable version of important fields extracted from the raw data. See schema below.
The included projects are the following:
- akka/akka
- devtools/hadley
- ProjectTemplate/johnmyleswhite
- stat-cookbook/mavam
- hiphop-php/facebook
- knitr/yihui
- shiny/rstudio
- folly/facebook
- mongo/mongodb
- doom3.gpl/TTimo
- phantomjs/ariya
- TrinityCore/TrinityCore
- MaNGOS/mangos
- bitcoin/bitcoin
- mosh/keithw
- xbmc/xbmc
- http-parser/joyent
- beanstalkd/kr
- redis/antirez
- ccv/liuliu
- memcached/memcached
- openFrameworks/openframeworks
- libgit2/libgit2
- redcarpet/vmg
- libuv/joyent
- SignalR/SignalR
- SparkleShare/hbons
- plupload/moxiecode
- mono/mono
- Nancy/NancyFx
- ServiceStack/ServiceStack
- AutoMapper/AutoMapper
- RestSharp/restsharp
- ravendb/ravendb
- MiniProfiler/SamSaffron
- storm/nathanmarz
- elasticsearch/elasticsearch
- ActionBarSherlock/JakeWharton
- facebook-android-sdk/facebook
- clojure/clojure
- CraftBukkit/Bukkit
- netty/netty
- android/github
- node/joyent
- jquery/jquery
- html5-boilerplate/h5bp
- impress.js/bartaz
- d3/mbostock
- chosen/harvesthq
- Font-Awesome/FortAwesome
- three.js/mrdoob
- foundation/zurb
- symfony/symfony
- CodeIgniter/EllisLab
- php-sdk/facebook
- zf2/zendframework
- cakephp/cakephp
- ThinkUp/ginatrapani
- phpunit/sebastianbergmann
- Slim/codeguy
- django/django
- tornado/facebook
- httpie/jkbr
- flask/mitsuhiko
- requests/kennethreitz
- symfony/xphere-forks
- reddit/reddit
- boto/boto
- django-debug-toolbar/django-debug-toolbar
- Sick-Beard/midgetspy
- django-cms/divio
- rails/rails
- homebrew/mxcl
- jekyll/mojombo
- gitlabhq/gitlabhq
- diaspora/diaspora
- devise/plataformatec
- blueprint-css/joshuaclayton
- octopress/imathis
- vinc.cc/vinc
- paperclip/thoughtbot
- compass/chriseppstein
- finagle/twitter
- kestrel/robey
- flockdb/twitter
- gizzard/twitter
- sbt/sbt
- scala/scala
- scalatra/scalatra
- zipkin/twitter
Importing and using
The following instructions assume an OSX or Linux based host.
MongoDB
$ wget http://ghtorrent.org/downloads/msr14-mongo.tar.gz
$ tar zxvf msr14-mongo.tar.gz
$ mongorestore
$ mongo msr14
mongo> db.commits.count()
601080
mongo> db.issues.count()
126308
MySQL
$ wget http://ghtorrent.org/downloads/msr14-mysql.gz
$ mysql -u root -p
mysql > create user 'msr14'@'localhost' identified by 'msr14';
mysql> create database msr14;
mysql> GRANT ALL PRIVILEGES ON msr14.* to msr14@'localhost';
mysql> flush privileges;
# Exit MySQL prompt
$ zcat msr14-mysql.gz |mysql -u msr14 -p msr14
$ mysql -u msr14 -p msr14
mysql> select language,count(*) from projects where forked_from is null group by language;
+------------+----------+
| language | count(*) |
+------------+----------+
| C | 10 |
| C# | 8 |
| C++ | 8 |
| CSS | 3 |
| Go | 1 |
| Java | 8 |
| JavaScript | 9 |
| PHP | 9 |
| Python | 10 |
| R | 4 |
| Ruby | 10 |
| Scala | 9 |
| TypeScript | 1 |
+------------+----------+
13 rows in set (0.01 sec)
FAQ
Answers to frequently asked questions
Why a new dataset?
For practical reasons. The dataset is small enough to be used on a laptop, yet rich enough to do really interesting research with it.
What are the hardware requirements?
We have succesfully imported and used both dumps into a 2011 MacBookAir with 4GB of RAM. Your mileage may vary, but relatively new systems with more than 4GB RAM should have no trouble with both databases. If you only need to use the MySQL data dump, the hardware requirements are even lower.
Why two databases? Do I need both?
Not necessarily. The MySQL database can readily cover many aspects of activity on Github. Perhaps the only reason to use the MongoDB dump is to analyse commit contents, branches affected by pull requests or milestones, which are not included in MySQL.
The relational DB schema
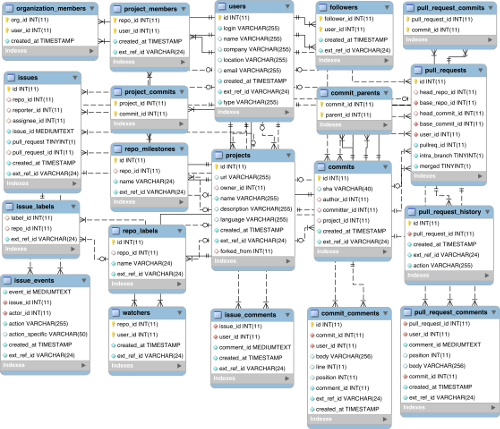
{kind=link}
Entities and their relationships
users
Github users.
- A user has a unique user name or email. May contain artificially generated user names, see
commitsbelow. - There are two types of
users,USERs andORGanizations. The second type defines a collection of users. organization_members
Users that are members of an organization.
- The
created_atfield is only filled in accurately for memberships for which GHTorrent has recorded a corresponding event. Otherwise, it is filled in with the latest date that the corresponding user or organization has been created.
projects
Information about repositories. A repository is always owned by a user.
- The
forked_fromfield is empty unless the project is a fork in which case it contains theidof the project the project is forked from. - The
deletedfield means that the project has been deleted from Github.
project_members
Users that have commit access to the repository.
The created_at field is only filled in accurately for memberships for which GHTorrent has recorded a corresponding event. Otherwise, it is filled in with the latest date that the corresponding user or project has been created.
commits
Unique commits.
- Each commit is identified globally through its
shafield. If the author or the committer has not configured his Github email address, no resolution to a User enty is possible. In that case, GHTorrent generates artificial users using the provided email in the Git commit author or committer fields. If the user then configures his Github account, GHTorrent will update the artificial user accordingly. - The
project_idfield contains a link to the project that this commit has been first associated with. This might not be the project this commit was initially pushed to, e.g. in case the fork is processed before the parent. Seeproject_commits. - The
project_idfield may be null when the repository has been deleted at the time the commit is processed. This situation might happen when retrospectively processing pull requests for a repository and the repository which the pull request originates from has been deleted.
commit_parents
The parent commit(s) for each commit, as specified by Git.
project_commits
The commits belonging to the history of a project.
More than one projects can share the same commits if one is a fork of the other.
commit_comments
Code review comments on commits.
These are comments on individual commits. If a commit is associated with a pull request, then its comments are in the pull_request_comments table.
followers
A follower to a user.
The created_at field is only filled in accurately for followships for which GHTorrent has recorded a corresponding event. Otherwise, it is filled in with the latest date that the corresponding user or follower has been created.
watchers
Users that have starred (was watched) a project
The created_at field is only filled in accurately for starrings for which GHTorrent has recorded a corresponding event. Otherwise, it is filled in with the latest date that the corresponding user or project has been created.
pull_requests
A pull request initiated from head_repo_id:head_commit_id to base_repo_id:base_commit_id
Pull requests can be in various states. The states and their transitions are recorded in the pull_request_history table.
The pullreq_id field is Github’s pull request unique identifier
The intra_branch field signifies that the head and base repositories are the same
If the head repository is NULL, this means that the corresponding project had been deleted when GHTorrent processed the pull request.
pull_request_history
An event in the pull request lifetime
The action field can take the following values
opened: When the pull request has been openedclosed: When the pull request has been closedmerged: When Github detected that the pull request has been merged. No merges outside Github (i.e. Git based) are reportedreoponed: When a pull request is opened after being closedsyncrhonize: When new commits are added/removed to the head repository
pull_request_commits
A commit associated with a pull request
The list is additive. This means if a rebase with commit squashing takes place after the commits of a pull request have been processed, the old commits will not be deleted.
pull_request_comments
A code review comment on a commit associated with a pull request
The list is additive. If commits are squashed on the head repo, the comments remain intact.
issues
An issue associated with a repository
- The
assigneefield is filed in with the user to which the issue was assigned at the time the issue was processed. - Issues have history recorded in the
issue_eventstable. - For every pull request, GHTorrent creates a corresponding issue. The
pull_request_idfield points to the associated pull request - The
issue_idfield is the unique identifier given to the issue by Github.
issue_events
An event on an issue
- The
actionfield can have the following values:subscribed: When a user subscribes to receive notifications about the issue.mentioned: When a user is mentioned by another user (@user notation)closed: When the issue has been closedreferenced: The issue was referenced in a commit (using the fixes: conventions)assigned: When the issue has been assigned to an actor.reopened: When a closed issue is reopenedunsubscribed: When a user unsubscribed from issue.merged: When the pull request pointed by the issue has been merged.head_ref_cleaned: (Not documented) ?head_ref_deleted: (Not documented) When the branch of the head repository has been deletedhead_ref_restored: (Not documented) When the head repository of a pull request has * been restored (using the restore branch functionality).
- The
action_specificfield gets filled in with the commit_id of the last commit when a pull request has been closed, merged or referenced.
issue_comments
An entry to the issue discussion. This table is always filled in with pull request (or issue) discussion comments, irrespective of whether the repo has issues enabled or not.
repo_labels
A label to be assigned to an issue affecting this repository.
issue_labels
A label that has been assigned to an issue
Example queries
List commits for a repository
select c.*
from commits c, project_commits pc, projects p, users u
where u.login = 'rails'
and p.name = 'rails'
and p.id = pc.project_id
and c.id = pc.commit_id
order by c.created_at desc
Get all actions for a pull request
select user, action, created_at from
(
select prh.action as action, prh.created_at as created_at, u.login as user
from pull_request_history prh, users u
where prh.pull_request_id = ?
and prh.actor_id = u.id
union
select ie.action as action, ie.created_at as created_at, u.login as user
from issues i, issue_events ie, users u
where ie.issue_id = i.id
and i.pull_request_id = ?
and ie.actor_id = u.id
union
select 'discussed' as action, ic.created_at as created_at, u.login as user
from issues i, issue_comments ic, users u
where ic.issue_id = i.id
and u.id = ic.user_id
and i.pull_request_id = ?
union
select 'reviewed' as action, prc.created_at as created_at, u.login as user
from pull_request_comments prc, users u
where prc.user_id = u.id
and prc.pull_request_id = ?
) as actions
order by created_at;
Get participants in an issue or pull request
select distinct(user_id) from
(
select user_id
from pull_request_comments
where pull_request_id = ?
union
select user_id
from issue_comments ic, issues i
where i.id = ic.issue_id and i.pull_request_id = ?
) as participants
Collections in MongoDB
Here is a list of collections along with the Github API URL they cache data from. All URLs need to be prefixed with https://api.github.com/. In MongoDB, each entity is by default indexed by the parameter fields in each corresponding URL (see also the actual default indexes).
| Collection name | Github API URL | Documentation URL |
|---|---|---|
| commit_comments | #{user}/#{repo}/commits/#{sha}/comments |
commit comments |
| commits | repos/#{user}/#{repo}/commits |
commits |
| events | events |
events |
| followers | users/#{user}/followers |
followers list |
| forks | repos/#{user}/#{repo}/forks |
forks list |
| issues | /repos/#{owner}/#{repo}/issues |
issues for a repo |
| issue_comments | repos/#{owner}/#{repo}/issues/comments/#{comment_id} |
issue comments |
| issue_events | repos/#{owner}/#{repo}/issues/events/#{event_id} |
issue events |
| org_members | orgs/#{org}/members |
organization members |
| pull_request_comments | repos/#{owner}/#{repo}/pulls/#{pullreq_id}/comments |
pull request review comments |
| pull_requests | repos/#{user}/#{repo}/pulls |
pull requests |
| repo_collaborators | repos/#{user}/#{repo}/collaborators |
repo collaborators |
| repo_labels | repos/#{owner}/#{repo}/issues/#{issue_id}/labels |
issue labels |
| repos | repos/#{user}/#{repo} |
repositories |
| users | users/#{user} |
users |
| watchers | repos/#{user}/#{repo}/stargazers |
stargazers |